Deep Learning
This gallery contains examples of how to use the most common open-source Deep Learning frameworks with SWAN.
The notebooks are intended to be run using GPU resources.
To use GPU resources in SWAN, you need to:
- Access SWAN from you browser: https://swan.cern.ch
- Select a software stack with GPU
- Note, to get the latest version of the tools used here select the 'bleeding edge' software stack
![]()
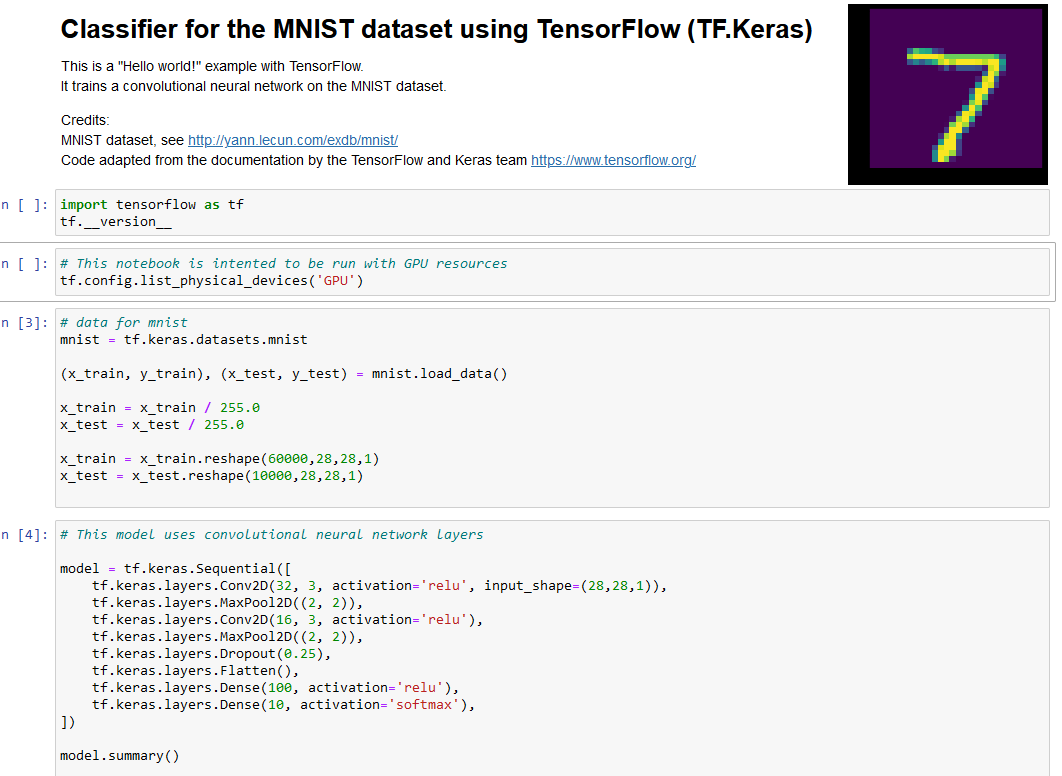
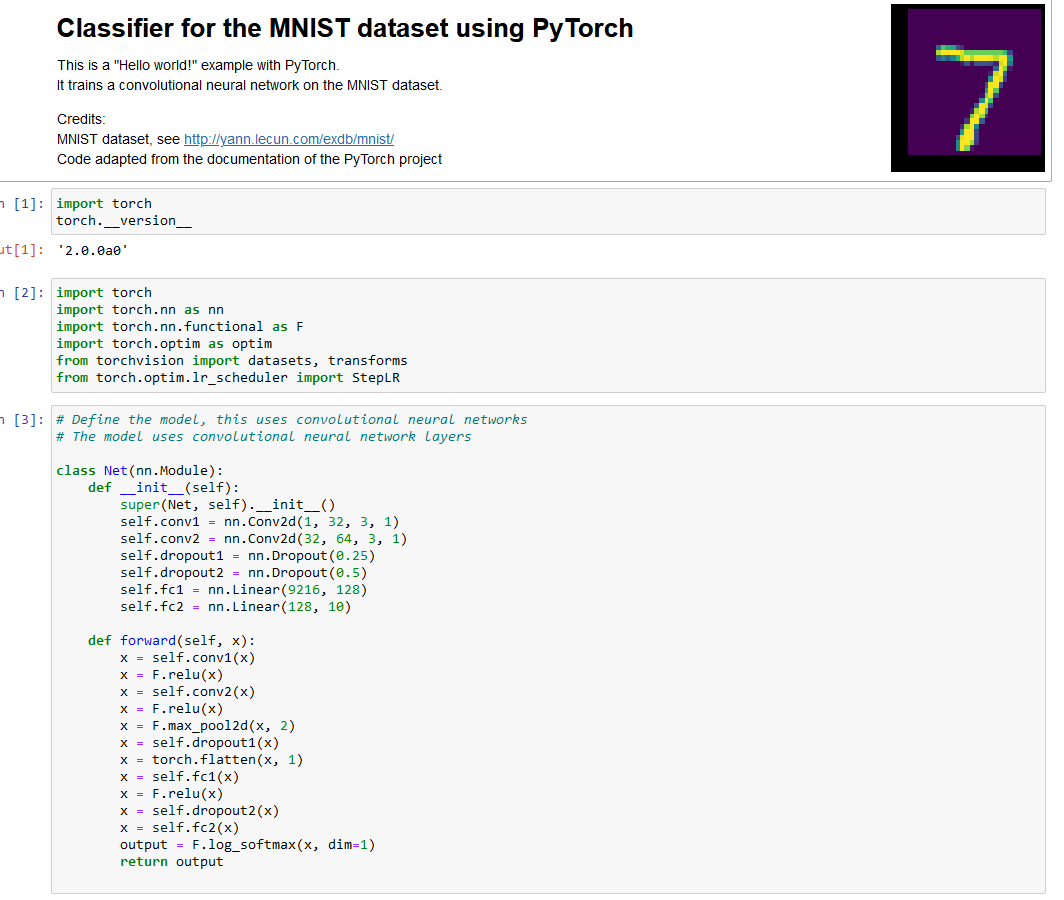
Getting started with Deep Learning
These notebooks implement a classifier for digit recognition using the MNIST dataset, it is a sort of "Hello World!" for Deep Learning.
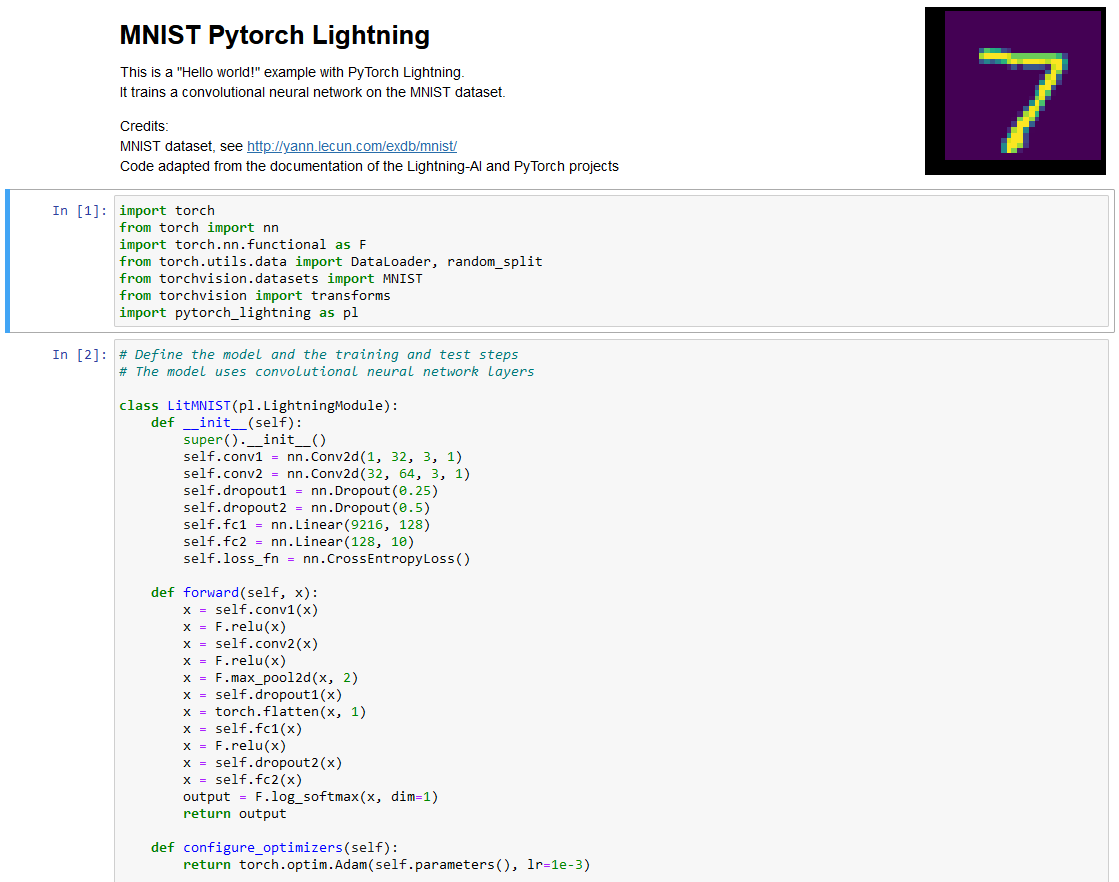
Deep Learning and basic Data pipelines
These notebooks provide examples of how to integrate Deep Learning frameworks with some basic data pipelines using Pandas to feed data into the DL training step.
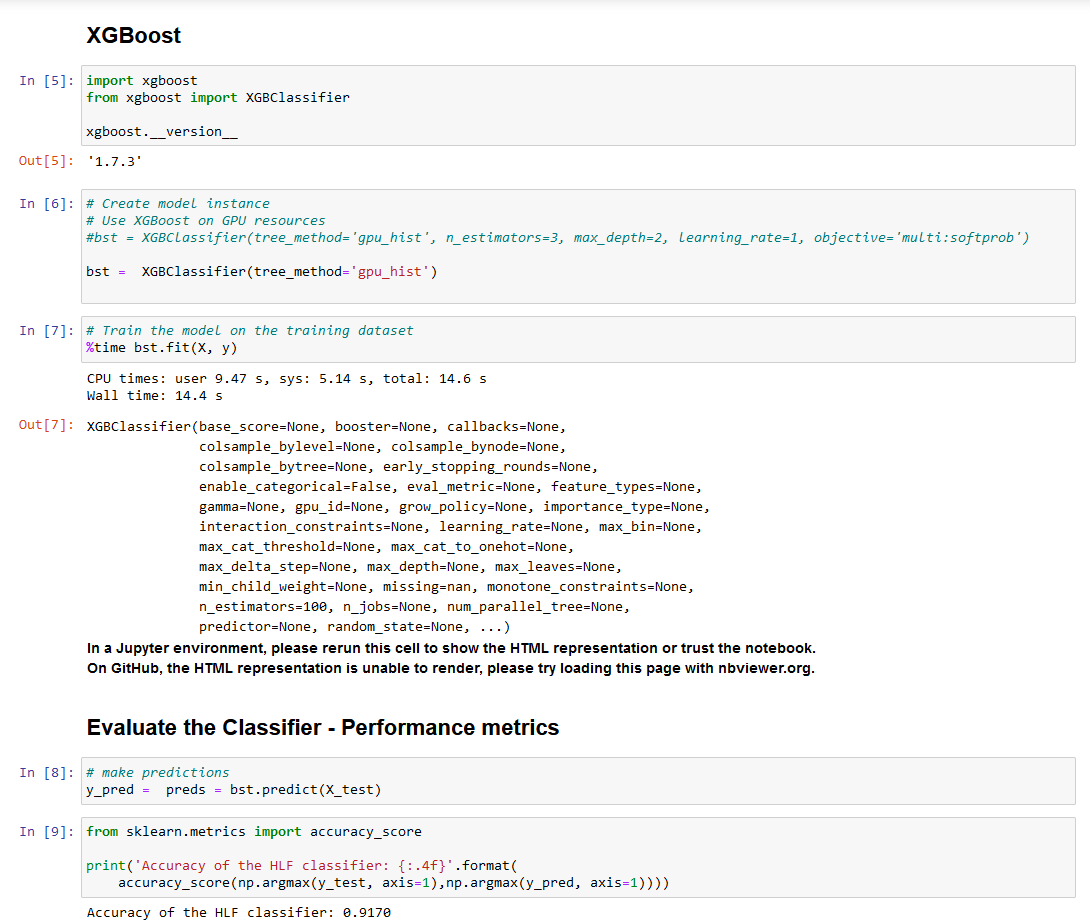
They implement a simple Particle classifier using different DL frameworks. The data is stored in Parquet format, which is a columnar format that is very efficient for reading,
it is processed using Pandas, and then fed into the DL training step.

TensorFlow classifier with Pandas
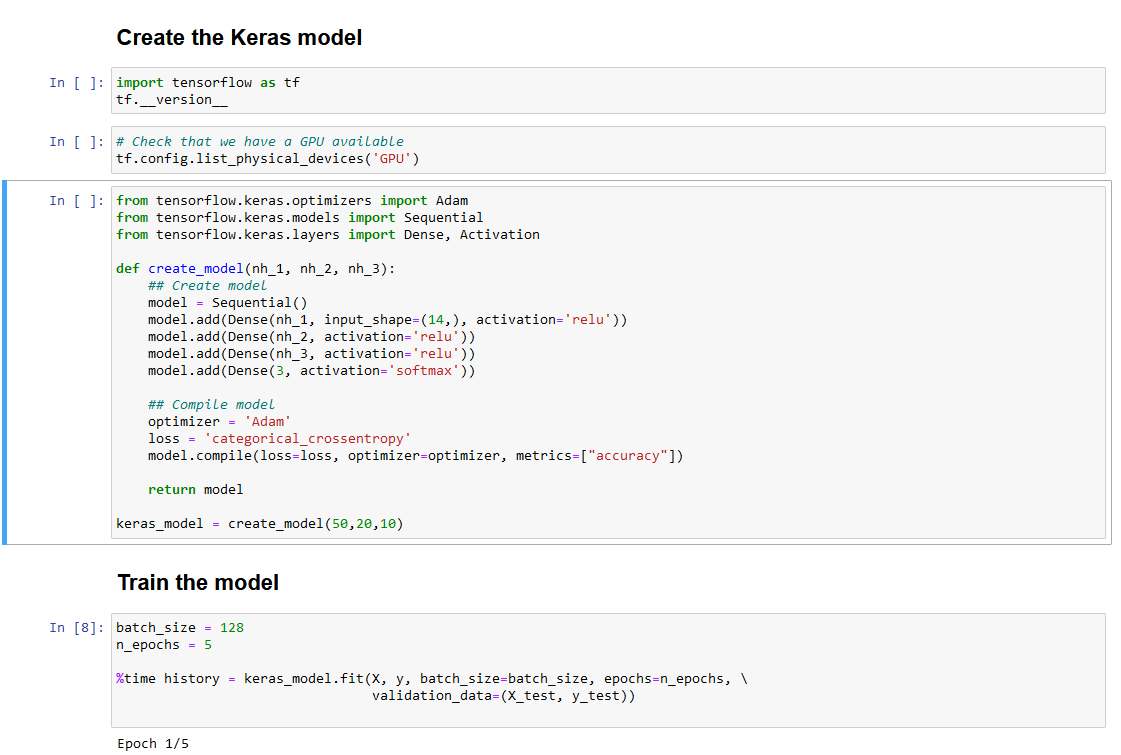
Pytorch classifier with Pandas
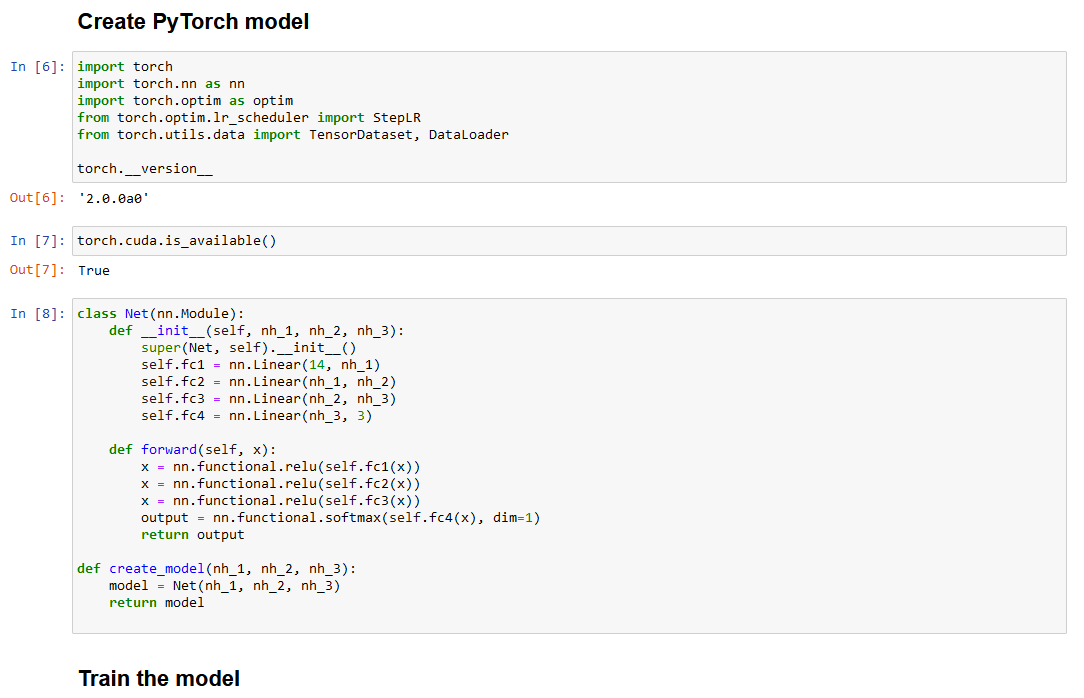
Pytorch Lightning classifier with Pandas
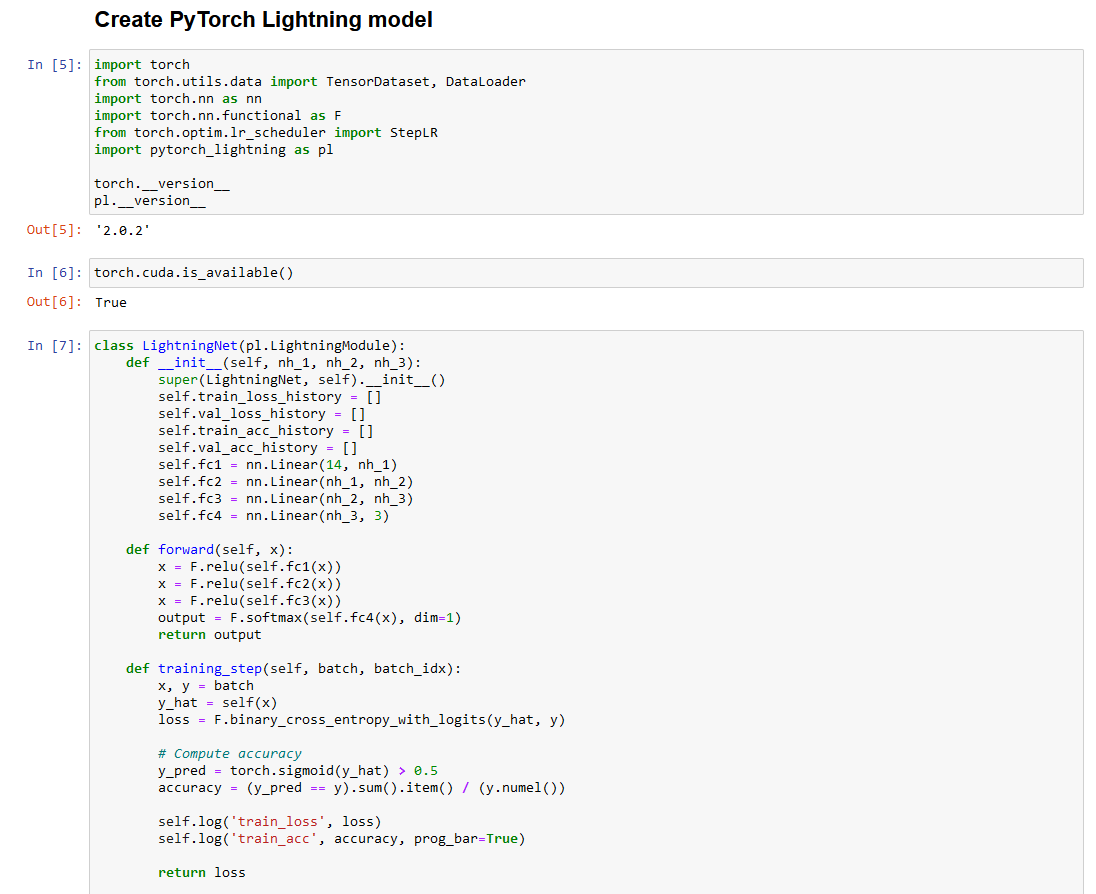
XGBoost classifier with Pandas
More advanced Data pipelines
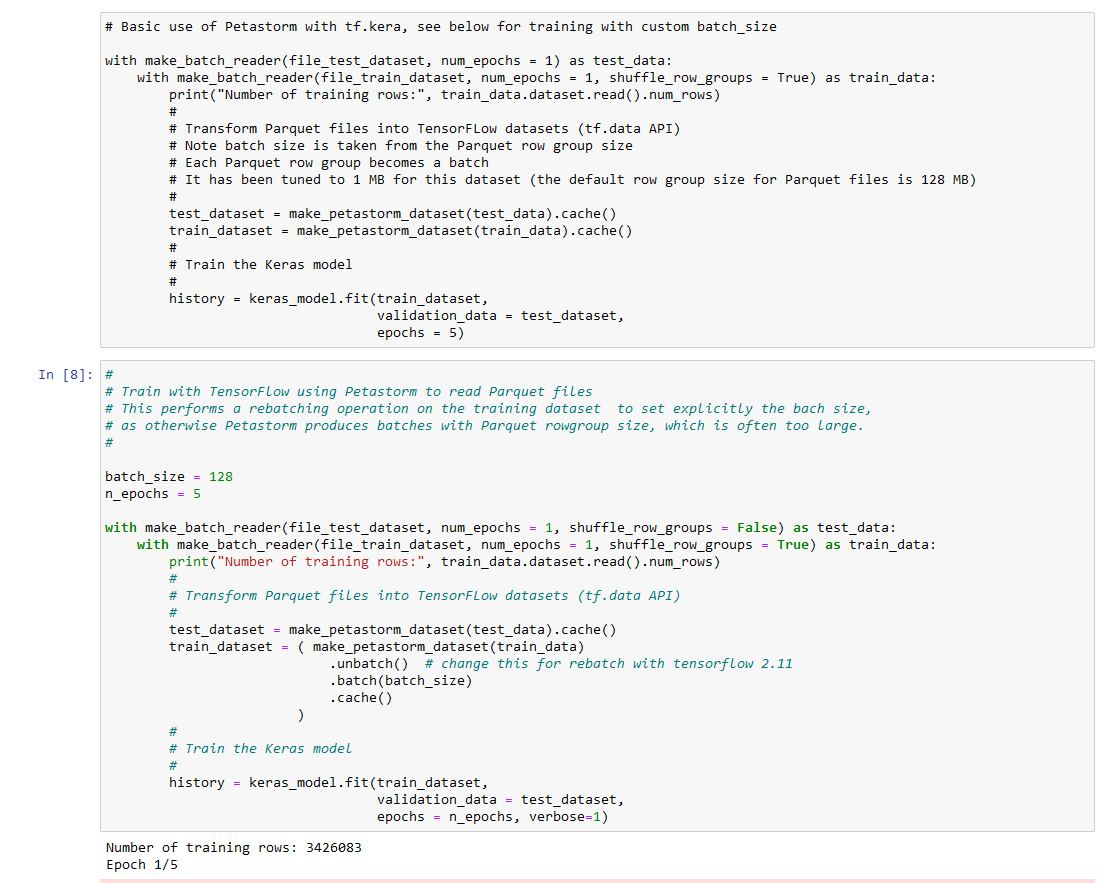
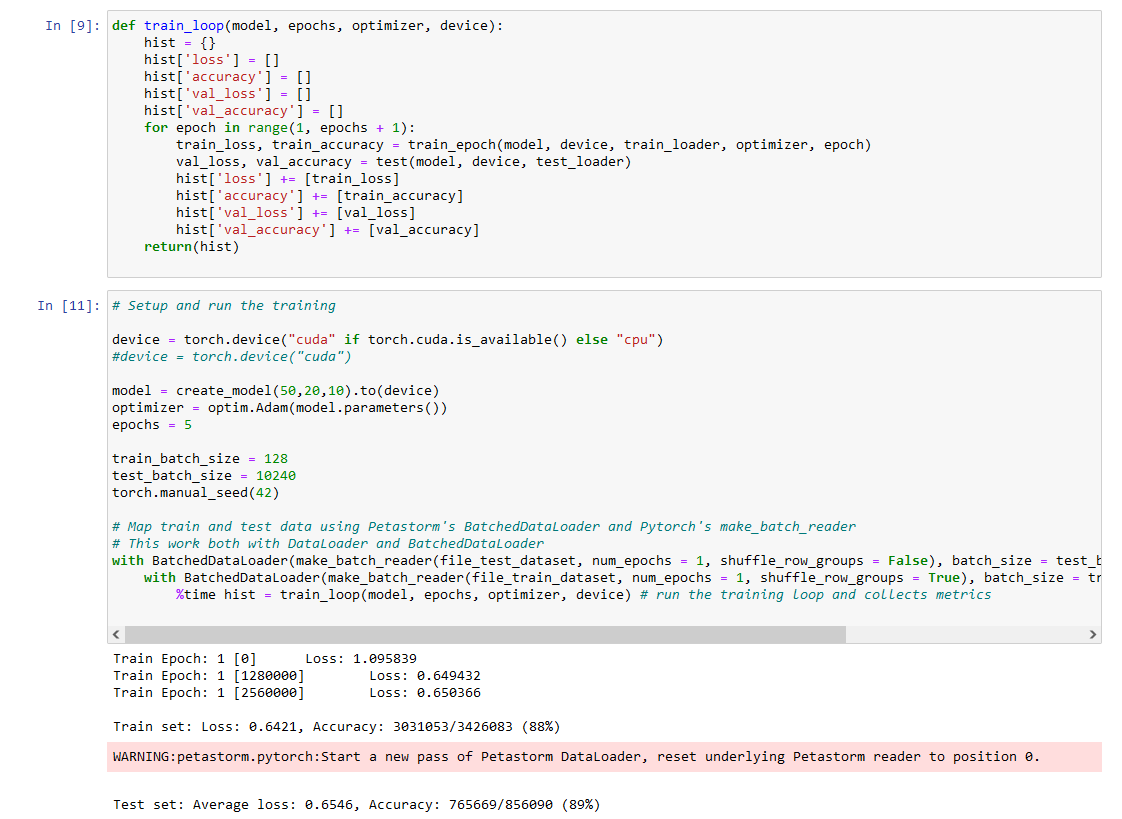
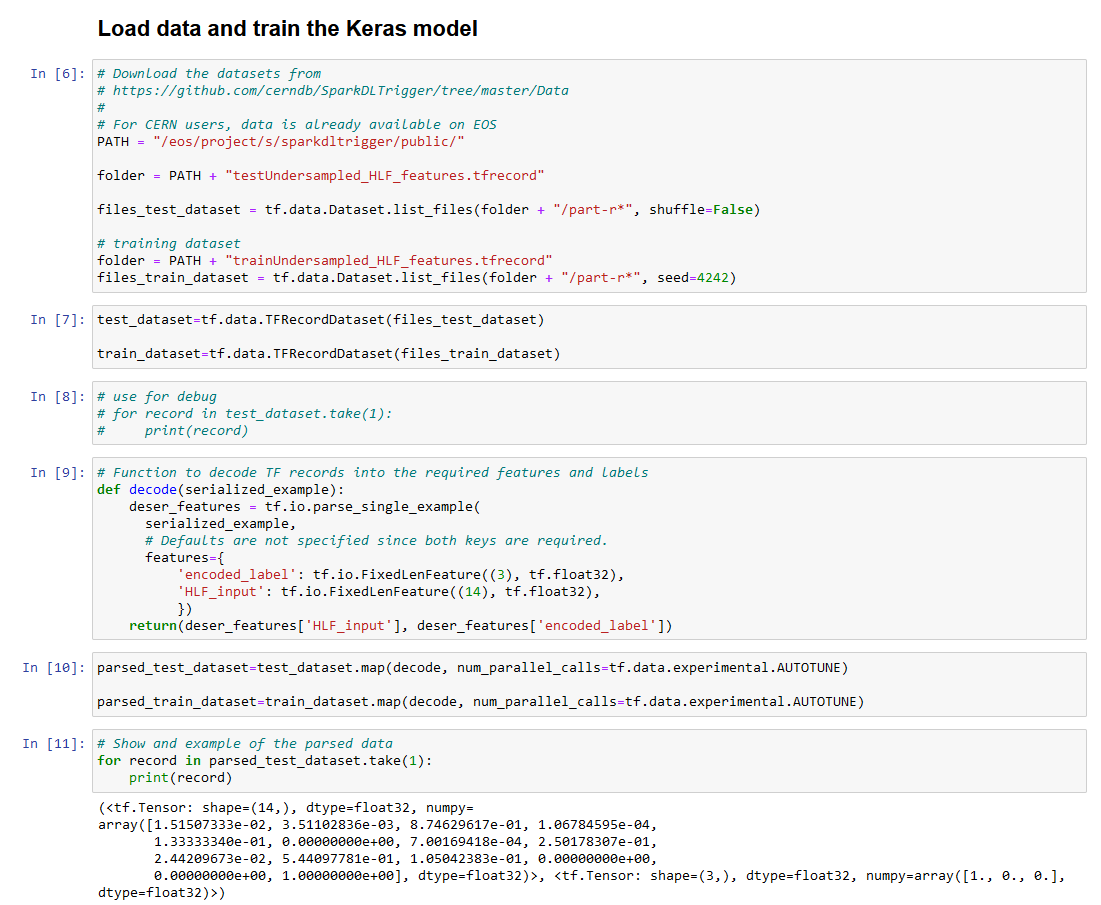
These examples show some more advanced data pipelines, useful for training with large data sets. They show how to use the Petastorm library to read data from Parquet files with TensorFlow and PyTorch, and how to use the TFRecord format with TensorFlow.
Additional complexity with models and data
These examples implement the same particle classifier as in the previous examples, but with a more complex model and bigger data set.